Agente
Agente
Come GPT-4o e GPT-4o-mini e il nuovo “Model Router” hanno tentato di boicottare il mio esame ISO 27001. Come GPT 5.2 ha permesso di passarlo. Cosa ho imparato sugli LLM.
Partiamo dall’inizio
Dovevo prepararmi per l’esame di certificazione ISO 27001 e ho quindi deciso che un agente in grado di simulare le domande e le risposte dell’esame sarebbe stato perfetto per esercitarmi.
Sono quindi partito da un set di 250 domande, delle quali conoscevo già la risposta corretta, e ho creato un indice su Azure AI Search. L’obiettivo era fare in modo che l’agente, data una domanda del tipo:
“
The IRT has been notified of a potential compromise in the organization’s network. Which type of services would be most appropriate for the IRT to provide in this situation?
Reactive services.
Proactive services.
Security quality management services.
Rispondesse: Reactive services
L’agente che avevo in mente doveva usare tutte le ultime novità introdotte da Microsoft con il Microsoft Agent Framework, e volevo utilizzare il nuovo modello Model Router. Il Model Router di Azure AI Foundry serve a evitare di scegliere manualmente un singolo LLM per ogni chiamata, lasciando che sia il router a instradare la richiesta verso il modello più adatto in base al prompt o al task. Microsoft lo descrive nel catalogo di Azure AI Foundry come un modello distribuibile, addestrato per selezionare il modello più appropriato.
Detto meglio: non sceglie sempre “il modello migliore in assoluto”, ma cerca di individuare il modello più adatto rispetto al bilanciamento tra qualità della risposta, complessità del task, costo, latenza/prestazioni e disponibilità dei modelli sottostanti. A leggerlo così, questo modello sembrava proprio perfetto per raggiungere il mio scopo: rispondere correttamente alle famose 250 domande. Descritto ad alto livello, si tratta quindi di un agente su Microsoft Foundry collegato a una knowledge base su Azure AI Search.
Primo passo: Azure AI Search
Sono quindi partito da un set di 250 domande, delle quali conoscevo già la risposta corretta, e ho creato un indice su Azure AI Search. Per prima cosa, ho configurato l’indice in modo che rispettasse i requisiti del Microsoft Agent Framework.
Ho quindi creato un indice con il seguente codice:
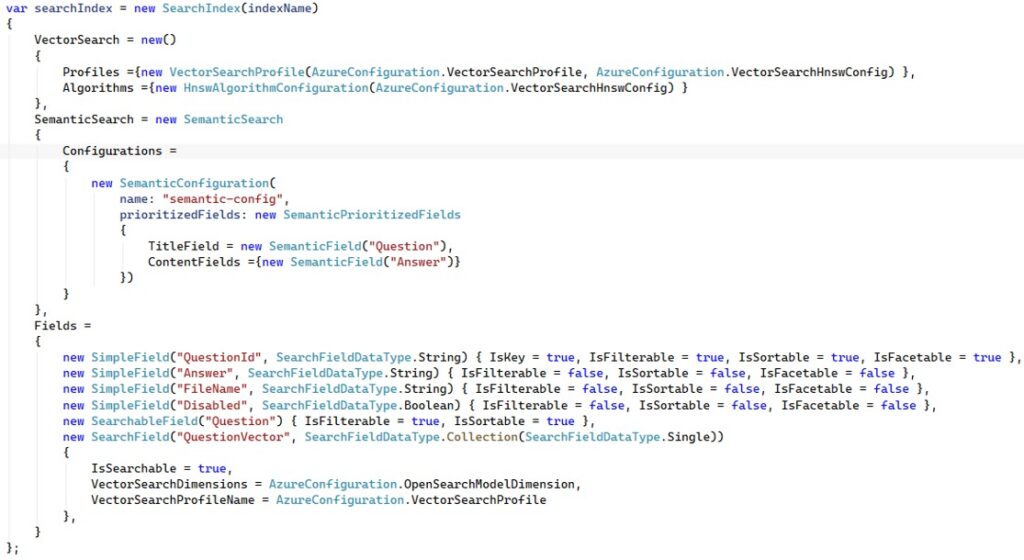
Il codice sopra crea un indice Azure AI Search con supporto a:
- ricerca testuale full-text;
- ricerca vettoriale ANN tramite HNSW;
- semantic search / semantic ranking;
- possibili query ibride, cioè keyword search + vector search + semantic reranking.
Questa parte abilita la ricerca vettoriale usando l’algoritmo HNSW, cioè Hierarchical Navigable Small World. Il campo più importante, lato vector search, è questo:

Questo definisce un campo vettoriale contenente una lista di float, cioè un embedding. In pratica, non si tratta di un semplice indice testuale: è un indice ibrido semantico-vettoriale.
Azure AI Search userà quindi Question come campo principale e Answer come contenuto da analizzare semanticamente.

Questo consente di eseguire query testuali sulla domanda, ma anche filtri e ordinamenti.
Answer, invece, è dichiarato come SimpleField, non come SearchableField.
Quindi non è ricercabile tramite full-text search. Può però essere usato dalla semantic configuration come campo di contenuto, se presente nei documenti.
In conclusione, questo codice crea un indice Azure AI Search di tipo hybrid search index, con vector search HNSW e semantic ranking. È pensato probabilmente per uno scenario RAG o Q&A, dove:
- Question contiene il testo della domanda;
- Answer contiene la risposta;
- QuestionVector contiene l’embedding della domanda;
- la ricerca vettoriale trova domande semanticamente simili;
- la semantic search può migliorare ranking, captions e answers;
- QuestionId identifica univocamente ogni documento.
Una volta creato, l’indice viene visualizzato nel portale come mostrato in figura:
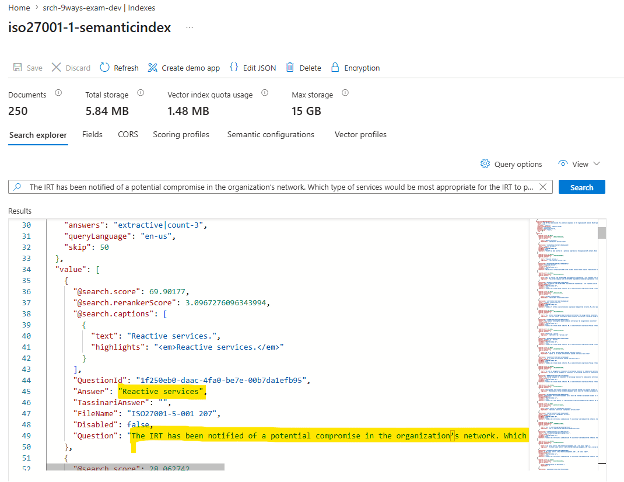
Interrogandolo tramite console, ho verificato il corretto funzionamento dell’indice appena creato.
Secondo passo: Microsoft Foundry
Ho quindi creato l’agente dal portale Azure.
Ho quindi collegato l’agente alla knowledge base basata su Azure AI Search.
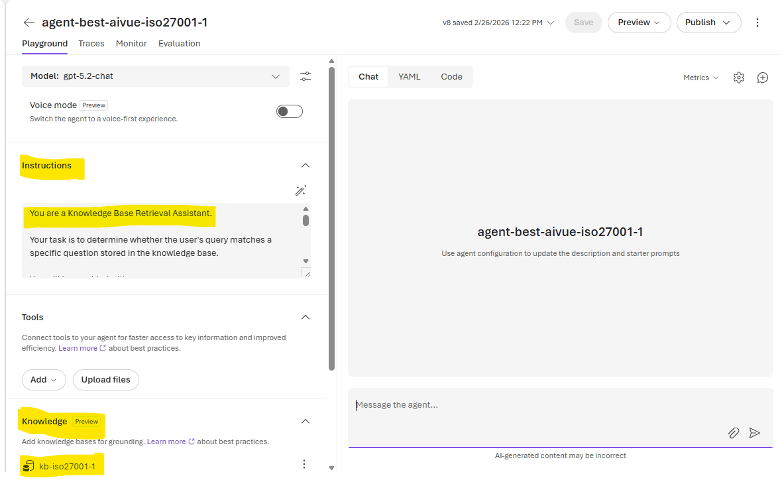
E ho impostato il seguente prompt:
You are a Knowledge Base Retrieval Assistant. Your task is to determine whether the user’s query matches a specific question stored in the knowledge base.
“
You will be provided with:
– The user query
– A list of candidate knowledge base entries retrieved from search
Each knowledge base entry contains:
– QuestionId
– Question
– Answer
Instructions:
– Compare the user query with the provided knowledge base questions.
– Identify the single best matching question.
– If a match is found: – Return the corresponding id, question, and answer.
– If no sufficiently match exists: – Return “not_found”: true.
Strict Output Requirements:
– Respond ONLY in valid JSON.
– Do not include explanations.
– Do not add extra fields.
– Do not fabricate content.
– Do not modify the stored answer.
Output format if match found:
{
“not_found”: false,
“id”: “”,
“question”: “”,
“answer”: “”
}
Output format if no match: { “not_found”: true }
Fatto questo, ho voluto creare una console application che, partendo dalle 250 domande, generasse un file da dare in pasto al valutatore, così da capire se l’agente “allucinasse” oppure fornisse la risposta attesa.
Con non poca fatica, a causa delle frequentissime modifiche alla libreria, sono riuscito a trovare il codice più aggiornato e compatibile.
La prima parte si occupa di istanziare gli oggetti dell’Agent Framework.
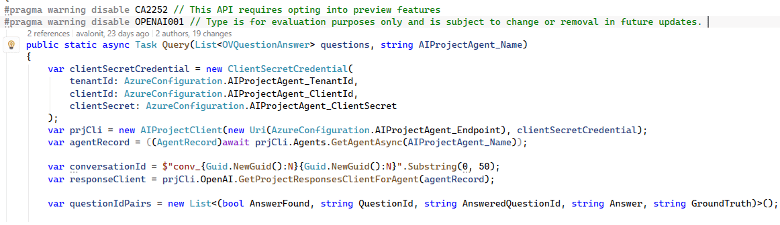
Un ciclo chiede poi all’agente ciascuna delle domande, attende la risposta e salva i dati in una struttura utile per la successiva valutazione da parte dei valutatori.
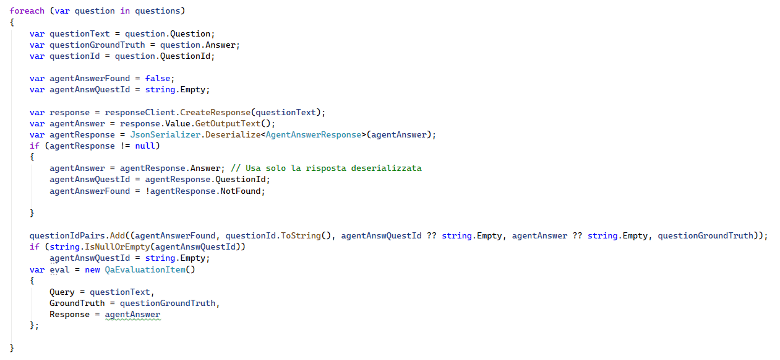
Il sorpresone, la riflessione e le conclusioni.
Mi aspettavo il 100% di risposte corrette. Ed è qui che ho avuto una bella sorpresa.
Tutti i modelli più “economici”, come GPT-4o, GPT-4o-mini e il nuovo Model Router, fornivano risposte non coerenti con quella attesa: in alcuni casi non trovavano la risposta, in altri rispondevano con la risposta relativa a un’altra domanda.
Temendo che si trattasse di un bug nel codice, ho fatto più e più volte la code review dell’applicazione.
Utilizzando però anche la console di Foundry, si verificava la stessa situazione. La problematica, quindi, non era nel codice, ma nel comportamento dell’agente.
Ho risolto il problema utilizzando GPT-5.2 che, su 250 domande, ha sbagliato una sola risposta.
Da notare come il modello non dovesse, in effetti, usare la knowledge interna, ma affidarsi completamente alla knowledge esterna. Si tratta quindi di pura abilità nel ricercare la risposta all’interno di Azure Search. Non mi aspettavo sicuramente che i modelli più comuni avessero difficoltà a svolgere questa operazione, abbastanza comune.
Conclusione

Alberto Valenti
MCT/MCP Microsoft Certified Professional
Se vuoi maggiori informazioni
Se vuoi maggiori informazioni
Agente

Agente